How to Use Python with the ESPN Fantasy API
September 25, 2022A step-by-step guide to build an ESPN fantasy football draft tool with python, pandas and google sheets

If you’re like me then you take fantasy football way too serious. You’re always looking for a way to get a leg up on the rest of the league.
While I can’t help you win your league, I can help you put yourself in a better position to win the draft with a little help from Python.
In this post you are going to use ESPN’s unofficial Fantasy API to get historical draft data with Python. This data includes the draft pick, the player drafted and the fantasy team that drafted said player.
You’ll use Pandas to clean up the data and export it out into a CSV file.
From there, you can upload the CSV file with all historical data into Google Sheets and use it to get a sense for the average count of positions drafted for each pick over the years.
Requirements:
- ESPN Fantasy Football League
- Python
- Pandas
- Google Sheets
I’ll walk through everything in a Jupyter Notebook and link out to my GitHub repo so you can clone it to use it as you wish. As always, you can follow along with Jabe in the video tutorial. You can also access my Github repo here.
Getting Started
If you log into your ESPN account and visit your fantasy league, you’ll see there is a History tab you can now access.

Within this view there is a “Draft Recap” which shows all of the picks by round.

You’ll notice three key columns:
- NO. (Pick Number)
- PLAYER
- TEAM
This data is obviously coming from somewhere before it is nicely formatted on this screen. To learn more about the data you can right-click and inspect the page, then click into the network tab.

Within the network tab you can see all the requests made after page load. Next thing you need to do is try and find the specific call which populates the draft information.
Searching for “draft” narrows down to a few options and the first view looks promising. If you click into it and go to the Preview tab you can see there is a boatload of json data which contains what you need.

Opening up the draftDetail and picks arrows show a total of 204 picks which matches up to a 17 round 12 team league draft (12 * 17 = 204 and the index starts at 0 so it will end at 203).
If you tab over to Headers you can see the Request URL that was used to retrieve this data:
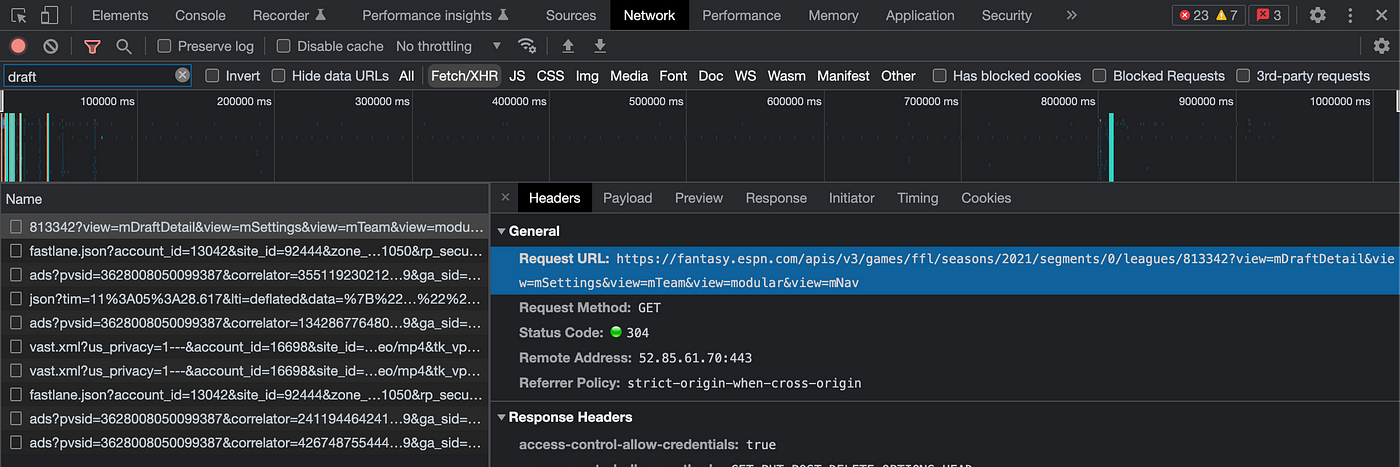
Note that this is the URL for any request after 2018. If you go back to a fantasy season beyond that you’ll notice a slightly different URL.
For simplicity sake, let’s use this historical URL since it (usually) works for all seasons.
There is one other key difference as pointed out by stmorse in his super helpful blog post,
Note: For some reason, the “current” URL returns a JSON, but the “historical” URL returns a JSON in a list of length one, thus the weird [0].
There are two key variables you want to focus on in this request.
The first is the seasonId. Here you can see that it is giving you draft details for the 2021 fantasy season because the string contains seasonId=2021.
Changing this year will change the data returned. Let’s swap out the year with the String.Format method. To use this method you use curly braces within the text to serve as a placeholder. You then call the string dot format method and pass in the year variable to the method which will replace the placeholder text when you run it. It should look like this
url = “https://fantasy.espn.com/apis/v3/games/ffl/leagueHistory/813342?view=mDraftDetail&view=mSettings&view=mTeam&view=modular&view=mNav&seasonId={}".format(season_id)The second variable is the leagueId. This is specific to the ESPN league you are in.
I will go into more detail in the next section but if your league is private then you need to include additional cookies in the header to signal that you have the proper permissions to get data from this league.
Let’s do the same thing you did with the season_id for the league_id. Pay attention that the league id comes first within the URL so you need to pass that in first to the string format method.
url = “https://fantasy.espn.com/apis/v3/games/ffl/leagueHistory/{}?view=mDraftDetail&view=mSettings&view=mTeam&view=modular&view=mNav&seasonId={}".format(league_id, season_id)Making API Requests with Python
Before doing anything make sure you have requests and pandas installed and you import both at the top of your notebook or file. For pandas it is common practice to import it as pd for short form.
import requests
import pandas as pdGetting Draft Details
You’ll use the Python request library to retrieve all the data you need from espn.com. For your purposes you will be using the GET method. To make a GET request, you’ll do so with requests.get().
There are three parameters you will pass with the GET request, the first is the URL, the second are the headers and the third are the cookies.
There are two cookies you need to include for private leagues. Again, these cookies tell ESPN that it is you making the URL call. You’re basically authenticating by providing cookies which only YOU can get access to by logging into your ESPN Fantasy league.
The two cookies are swid and espn_s2.
Inspect the draft history webpage again then navigate back to your headers tab and search for these within the Request Headers. A simple cmd + F lets you identify these within a big string blob.

To make it easy, let’s save this information into an espn_cookies variable which we will pass into the request call:
espn_cookies = {“swid”: “{46299BEC-CE08–4042–9D6F-CB41B89885EE}”, “espn_s2”: “AEBZoZ5pskd4UFxLIVgLTWjp8HFIwSn18Xhj7K7beiMLDnVmEj35PviMGsDwr8JwxFkVL5Szm%2FDNg5XL4wBkIh1HbVjZfZAe6%2Br7CmM996QrcsNAU0Sir1DBP7THgiEz8My9wXJQPaHpPMYHFeBVeHaO5uQUwDPcKaxc1xg5bHc1MCBXioQ1uGF7JQ5KYHK%2Bz4uRth1Obnfr1gP9KUBM0xgiVk4McqHFW0WtMibtMRhTBKlU%2BNaWHe6LSuCWG8Au6PcQ90C%2BNEpLO7VJd9JeXStA”}Let’s also create a headers variable and save the required headers in there. For the player_info call later on you will need to add additional info to the headers:
headers = { ‘Connection’: ‘keep-alive’,
‘Accept’: ‘application/json, text/plain,
*/*’, ‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36’,
}Now if you save the request URL into a url variable you can make the request call and save the response into a variable called r so you can more easily inspect and access the data you want.
r = requests.get(url, headers=headers, cookies=espn_cookies)
espn_raw_data = r.json()If you print this you can see that it returns a lot of info, more than what you need.
Again, you want to access the pick information which is nested within the draft detail. Because you used the historical API call, you have to get the json within a list which means accessing it via the fancy [0].
espn_draft_detail = espn_raw_data[0]
draft_picks = espn_draft_detail[‘draftDetail’][‘picks’]From there you can save the data into a draft_picks list and then turn that list into a pandas dataframe with this line of code.
df = pd.DataFrame(draft_picks)Lastly, all you want are the following three columns:
- overallPickNumber
- playerId
- teamId
So you can create a new data frame and filter on these three columns.
draft_df = df[[‘overallPickNumber’, ‘playerId’, ‘teamId’]]Great! You have all the historical draft data for a given year!
But wait, this isn’t super helpful because it just has a playerId and a teamId… Without being a supercomputer you don’t really know what player that is which means we don’t know the position of that player.
Let’s head back to the network tab and see if there is more info you can use.
Getting Player Info
If you search for “player” instead of “draft” you’ll find another call which looks to include information about the players.

Looking at the response and it appears it has exactly what you need. You currently have the playerId in your dataframe but still need to join that on another key so you can get the player name and more importantly the player’s position.
Let’s create another request that gets this info and stores it into a pandas dataframe. From there you can eventually join the data frames. The URL for this call can be grabbed from the Headers tab. You can use the string method again to swap out the year:
url = “https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}/players?scoringPeriodId=0&view=players_wl".format(season_id)Now, through my own trial and error I discovered that you need to pass an additional header into this request if you don’t want ESPN filtering the response. If you fail to include this header you will only get 50 players returned out of the possible 5081. There are so many players because the response includes each D/ST player for the crazies which use individual defensive players in fantasy.
With the help of an engineering friend smarter than myself, I noticed the following was being passed in the request on the site:
x-fantasy-filter: {“filterActive”:null}
x-fantasy-platform: kona-PROD-d8fba14d942cfef237ca6d6cc3ba9de27b91ae37
x-fantasy-source: konaI copied over my header from another blog post, How To Access Live NBA Play-By-Play Data, and added in this additional filterActive:null to prevent the response from being filtered.
Your headers should look like this:
headers = {
‘Connection’: ‘keep-alive’,
‘Accept’: ‘application/json, text/plain, */*’,
‘User-Agent’: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36’,
‘x-fantasy-filter’: ‘{“filterActive”:null}’,
‘x-fantasy-platform’: ‘kona-PROD-1dc40132dc2070ef47881dc95b633e62cebc9913’,
‘x-fantasy-source’: ‘kona’
}From here you can pass in the header argument to your get request, on top of the URL and cookies. Save the response in player_data.
url = “https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}/players?scoringPeriodId=0&view=players_wl".format(season_id)
r = requests.get(url,
cookies=espn_cookies,
headers=headers)
player_data = r.json()Similar to before, you’ll have all the data you need in a mega player_data list. You need to convert it into a dataframe, grab only the columns you want and rename id to player_id to make it easier for to join on it.
df = pd.DataFrame(player_data)
# get only needed columns for players
player_df = df[[‘defaultPositionId’,’fullName’,’id’,’proTeamId’]]
# rename id column for inner join
player_df.rename(columns = {‘id’:’player_id’}, inplace = True)Fantastic. You now have the draft data and the additional player info that will give you everything we need.
The next section is purely a nice-to-have if you also like to see the team that the player is on. It makes it easier to scan later on in my opinion.
Getting Team Info
Let’s run through the same step you did for the player_info but grab a team_info call instead. I am not going to go into a lot of detail here but drop a comment if you run into any issues.
Your code should look like this:
url = “https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}?view=proTeamSchedules_wl".format(season_id)
r = requests.get(url, cookies=espn_cookies)
team_data = r.json()
team_names = team_data[‘settings’][‘proTeams’]
df = pd.DataFrame(team_names)
# get only needed columns for teams
team_df = df[[‘id’, ‘location’, ‘name’]]
team_df[“team name”] = team_df[‘location’].astype(str) +” “+ team_df[“name”]
# rename in column
team_df.rename(columns = {‘id’:’team_id’}, inplace = True)One new thing here was joining two columns to make one team name column. Notice that you have the proTeamId in the player_info call which you can join on team_id here for your mega dataframe. This will be covered next.
Creating Python Functions
In the future you’ll want to get the draft details, player info and team info for each historical season. Instead of running the code each time and saving it into its own dataframe, I recommend turning each of these previous sections into a standalone function.
For the most part, the function will take in a few inputs, such as the season_id, league_id, headers and cookies, and return a dataframe. You can really just wrap everything you’ve done so far and replace a few of the variable items.
Draft Details Function
# get draft details
def get_draft_details(league_id, season_id):
# newest API v3 url
#url = "https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}/segments/0/leagues/{}?view=mDraftDetail&view=mSettings&view=mTeam&view=modular&view=mNav".format(season_id, league_id)
url = "https://fantasy.espn.com/apis/v3/games/ffl/leagueHistory/{}?view=mDraftDetail&view=mSettings&view=mTeam&view=modular&view=mNav&seasonId={}".format(league_id, season_id)
r = requests.get(url,
cookies=espn_cookies)
espn_raw_data = r.json()
espn_draft_detail = espn_raw_data[0]
draft_picks = espn_draft_detail['draftDetail']['picks']
df = pd.DataFrame(draft_picks)
# get only columns we need in draft detail
draft_df = df[['overallPickNumber', 'playerId', 'teamId']]
return draft_dfPlayer Info Function
# get player info
def get_player_info(season_id):
url = "https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}/players?scoringPeriodId=0&view=players_wl".format(season_id)
r = requests.get(url,
cookies=espn_cookies,
headers=headers)
player_data = r.json()
df = pd.DataFrame(player_data)
# get only needed columns for players
player_df = df[['defaultPositionId','fullName','id','proTeamId']]
# rename in column
player_df.rename(columns = {'id':'player_id'}, inplace = True)
return player_dfTeam Info Function
# get team information
def get_team_info(season_id):
url = "https://fantasy.espn.com/apis/v3/games/ffl/seasons/{}?view=proTeamSchedules_wl".format(season_id)
r = requests.get(url,
cookies=espn_cookies)
team_data = r.json()
team_names = team_data['settings']['proTeams']
df = pd.DataFrame(team_names)
# get only needed columns for teams
team_df = df[['id', 'location', 'name']]
team_df["team name"] = team_df['location'].astype(str) +" "+ team_df["name"]
# rename in column
team_df.rename(columns = {'id':'team_id'}, inplace = True)
return team_df
Again, having these as functions will make it easier to loop through seasons later on.
Merging Dataframes
Right now you have three separate functions all storing information in three separate pandas dataframes. This is a great start but you ultimately want them all in one dataframe so you can export it as a CSV file.
To accomplish this, you’ll merge dataframes together using certain columns as keys.
First things first, run your new functions and save them into descriptive dataframes. I chose the following names:
# get all needed info for the year
draft_df = get_draft_details(league_id, season_id)
player_df = get_player_info(season_id)
team_df = get_team_info(season_id)
After that you can merge the tables with an inner join. To use merge within pandas you need to call out which type of join it will be and which two columns you want to join on.
Let’s start with the draft_df dataframe and player_df dataframe which we can inner join on our respective player ids:
# merge tables together and save into a new df
df2 = pd.merge(draft_df, player_df, how=”inner”, left_on=”playerId”, right_on = “player_id”)From there you can merge the newly created df2 with the team_df dataframe to add in the team information:
# merge tables together and save into a new df
final_df = pd.merge(df2, team_df, how=”inner”, left_on=”proTeamId”, right_on = “team_id”)Beautiful. Now you’re rocking a sweet new dataframe with a lot of information. The catch is, it still has a few id related columns and some funky column names. You can touch this up though with some renaming.
Cleaning Dataframes
Mapping Positions
Within your dataframe you will see a defaultPositionId column. For your purposes of understanding the total count of each position drafted by a certain pick, your life will be easier when you see the actual position instead of the positionId.
To clean this up you can create a position_mapping dictionary which you’ll pass into a dataframe replace call. Dictionaries can be used to specify different replacement values for different existing values. The positionIds you want to replace with new string values are:
position_mapping = {
1: ‘QB’,
2: ‘RB’,
3: ‘WR’,
4: ‘TE’,
5: ‘K’,
16: ‘D/ST’
}You will dot replace the defaultPositionId with this newly created position_mapping dictionary by running the following:
# rename columns and map values for easier consumption. Save to new dataframe
league_draft = final_df.replace({“defaultPositionId”: position_mapping})Now in the dataframe you’ll see the positions as strings instead of as integer defaultPositionIds.
Mapping Fantasy Team Names
Similar to positions, you’ll want to do the same for your fantasy team names so you know exactly who drafted who. Merely replace the Team number with the name of your league members.
league_teams = {
1: ‘Team 1’,
2: ‘Team 2’,
3: ‘Team 3’,
4: ‘Team 4’,
5: ‘Team 5’,
6: ‘Team 6’,
7: ‘Team 7’,
8: ‘Team 8’,
9: ‘Team 9’,
10: ‘Team 10’,
11: ‘Team 11’,
12: ‘Team 12’
}You’ll then run the same dot replace method but this time replacing teamId with your league_teams:
league_draft_info = league_draft.replace({“teamId”: league_teams})Pay attention to the new chain of dataframes you’re creating. Instead of overriding the dataframe each time, you are creating a new one and saving the data into that one. This makes it easier to fix any mistakes line by line. Great. Almost there.
Renaming Dataframe Columns
Lastly, you can touch up a few of the remaining columns to make them more readable. Before doing that you can filter down to only the columns you need again.
From there, you can pass in a dictionary directly into the dot replace method with each current column name and desired replacement name.
# filter for only the columns you need
league_draft_final = league_draft_info[[‘overallPickNumber’, ‘teamId’, ‘defaultPositionId’, ‘fullName’, ‘team name’]]
# rename columns to make them more readable league_draft_final.rename(columns = {‘overallPickNumber’:’pick’, ‘teamId’:’geebs_team’, ‘defaultPositionId’:’position’, ‘fullName’:’player’, ‘team name’: ‘player_team’}, inplace = True)
On that last rename call you passed in the inplace = True parameter. For more info on that, you can read my helpful blog post: Explaining the Inplace Parameter for Beginners
Boom!
Looping Over Every Year
Now that you have all the basic building blocks, the last sep is to create a for loop which loops over every year and stores it into a new empty dataframe.
First step is to create a list with all the eligible fantasy years. My league dates back to 2012 so let’s hit it.
# have all eligible draft years
years = [
‘2012’,
‘2013’,
‘2014’,
‘2015’,
‘2016’,
‘2017’,
‘2018’,
‘2019’,
‘2020’,
‘2021’,
]Next, you need to create an empty dataframe because you are going to loop over every year and append each year’s draft details into this dataframe.
One additional line of code you’ll want to add within this for loop is creating a new column which stores the draft year. You don’t need this when looking at a single season but when you’re looking at 10 seasons of data you’ll need a way to groupby each one.
So all in all your for loop should look like this:
# create an empty dataframe to append to
all_drafts_df = pd.DataFrame()
# loop over all the years
for year in years:
print(year)
# get all needed info for the year
draft_df = get_draft_details(league_id, year)
player_df = get_player_info(year, headers)
team_df = get_team_info(year)
# merge tables together
df2 = pd.merge(draft_df, player_df, how="inner", left_on="playerId", right_on = "player_id")
final_df = pd.merge(df2, team_df, how="inner", left_on="proTeamId", right_on = "team_id")
# rename columns and map values for easier consumption
league_draft = final_df.replace({"defaultPositionId": position_mapping})
league_draft_info = league_draft.replace({"teamId": league_teams}) league_draft_final = league_draft_info[['overallPickNumber', 'teamId', 'defaultPositionId', 'fullName', 'team name']]
league_draft_final.rename(columns = {'overallPickNumber':'pick', 'teamId':'geebs_team', 'defaultPositionId':'position', 'fullName':'player', 'team name': 'player_team'}, inplace = True)
league_draft_final['year'] = year
league_draft_final['year'] = league_draft_final['year'].apply(str)
all_drafts_df = all_drafts_df.append(league_draft_final)If you take a sample of your dataframe you should see a nice collection of picks over the years
all_drafts_df.sample(10)Exporting Dataframe to a CSV
If your intention is to upload this information into Google Sheets then I recommend exporting it as a CSV file. Luckily, pandas provides a really nice and easy way to do this.
# export into CSV
all_drafts_df.to_csv(‘fantasy_football_drafts.csv’, index=False)In the future, if you ever want to upload this csv back into a dataframe, you can run the following:
# read in CSV
new_df = pd.read_csv(‘fantasy_football_drafts.csv’)Creating a Pivot Table in Google Sheets
Congrats on making it this far. If you recall, the initial intention of this post was to help you analyze your fantasy leagues draft history. One key element of this is understanding how many positions are generally drafted by each pick.
Armed with this information you can run through some general mock drafts if you have a list of rankings for each position. To start, create a new empty google sheet and import in your CSV file.

From there, you will want to generate a pivot table with this information.
Within the pivot table editor, you can specify which data you want for the rows, columns and values. For your purposes you’ll want to place position in rows, year in columns (both ordered by ascending) and then player in Values.

For the Values, you actually want to count the uniques. You don’t necessarily care if Patrick Mohomes or Josh Allen was drafted first or second, you care that there are 2 QBs off the board.
Great. Pivot Tables also offer Filtering logic. You can think of this filter as being the draft pick you are projecting. So if you plug in the 44th pick, what you’re actually telling the pivot table is to show the count of each position drafted by the 44th pick over the years.
You can then plot this in a chart to see any trends.

Lastly, to make this more useful, you can start a new sheet which takes the draft pick as an input and outputs that same chart.

The only thing you need to change is turning the filter into a custom formula within the pivot table editor. You can use the following:
Custom formula is =pick<=ADP!B4
Summary
Well there you have it. A step-by-step guide to help you dominate your fantasy football draft.
You:
- Used Python to get historical draft data from ESPN’s (unofficial) API
- Cleaned and munged the data in Pandas
- Exported the dataframe into a CSV file
- Created a Google Sheet Pivot Table to draw draft insights
I hope you found this post useful. As always you can find more of these on my Learn with Jabe Youtube channel. Please feel free to drop any comments or questions and I’ll do my best to get back to you in a timely manner.
New posts delivered to your inbox
Get updates whenever I publish something new. If you're not ready to smash subscribe just yet, give me a test drive on Twitter.